编译时你在做什么?有没有空?可以来拯救吗?
太陽の傾いたこの世界で
通常写程序的时候,我们会更关注于程序的代码(main.c)和最终形成的可执行文件(main)。对于程序员来说,这两个部分的确是最重要的,甚至说90%的情况下都不用去管其它部分。现代的编译器非常智能,它们会帮你处理好很多东西(表扬 clang [klæŋ] ) 。但是,在编译的过程中,除了你的源代码和最终的可执行程序,其它部分,也就是编译器做的那部分,也应该得到关注。所以,这次的workshop将会关注程序运行背后的故事。事实上,有很多bug是因为忽视了编译器的运作原理而导致的。
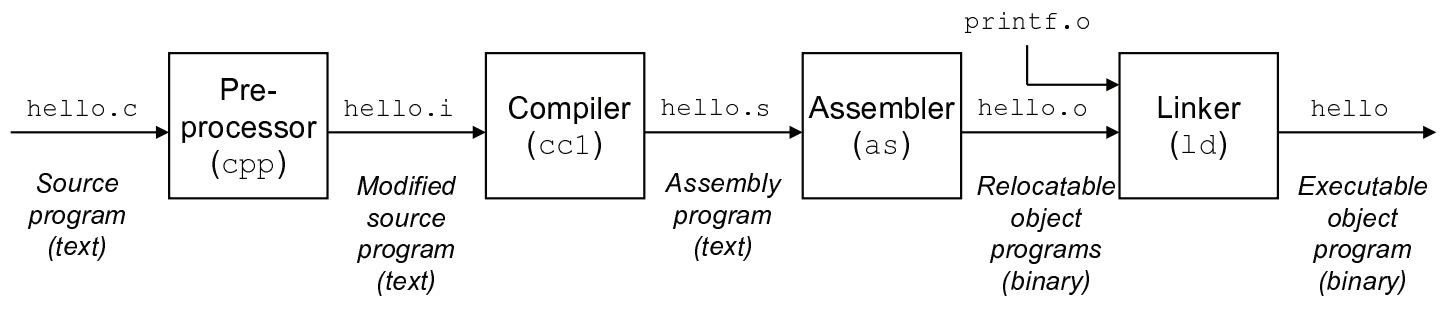
现在我们学的大部分语言都是高级语言,而CPU认的却是二进制的机器码。当我们在编译程序的时候,编译器会将我们的高级语言翻译成低级的汇编语言。而在程序运行的时候,会将汇编语言翻译成机器码。这是程序的运作原理。
この戦いが終わったら
C作为一门不会对内存检查的语言,因此很多的操作会超出一个变量的边界去影响下一个变量,举一个例子:
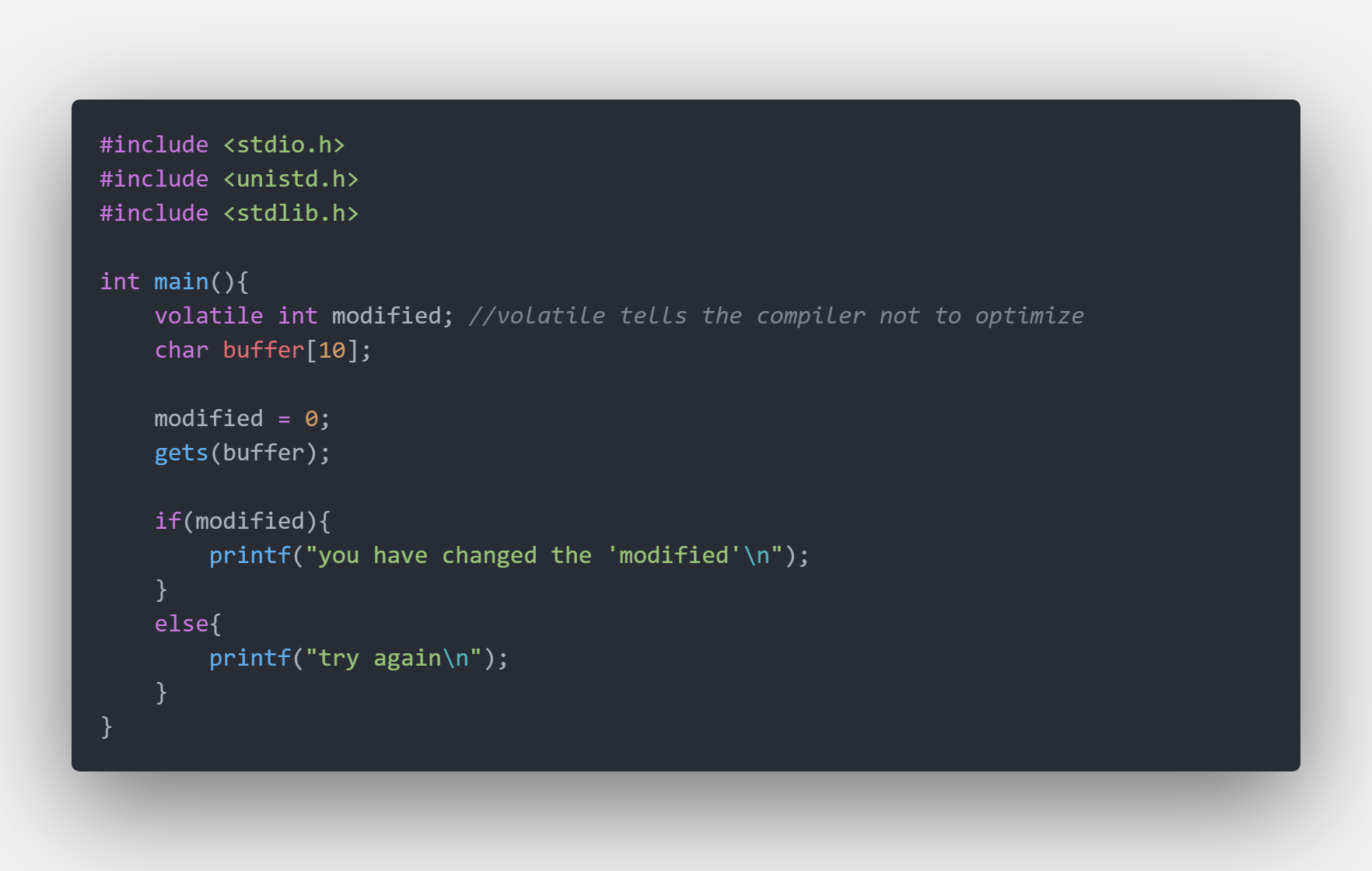
有没有什么办法来改变变量modified的值呢?
可以同时输入10个A 和11个A 来康康结果:

可以看到,在输入了超过10个字符后,modified的值被改变了。原因在于数据的存储方式。计算机中有一个叫内存空间的东西,它存放着所有的变量。一般情况下,一个变量将会分字节存在内存空间中,如左图所示。而buffer[10] 开辟了10个字节的内存空间,modified在buffer[10]上面开辟了4个字节的空间(通常指x86,数据是这么排列在计算机中的)。当我们输入了10个A以后,buffer[10]的内存空间被用完了,而gets()函数并不会对空间的边界进行检查,所以当第11个A输入了以后,A被挤到了(int)modified的内存空间,所以原本是0的modified不再是0(实际上modified的值 是 A的askll值 65 )所以gets非常不安全当然这是非常特殊的情况,因为我们一般用的是cin或者scanf甚至在VS中用的是更加安全的scanf_s。
同样的,cin的运作原理也可以这么解释:在输入回车之前,所有的输入都会存在一个缓冲区中,程序会根据分隔符或者变量类型来选择读入合适的数据。ifstream 同理。
这个程序是一个很简单的堆栈溢出的例子,我觉得它对理解 内存空间有一定帮助。
![]()
说到这里,Stackoverflow 直译过来就是堆栈溢出 XD。
而在这个具体的例子中:内存空间(栈)是这样的:
可以看出,内存的排列顺序是自下而上的,或者说叫做小端序。将会有一个叫做栈指针的指针指向当前的内存并对内存进行操作。
有诗云:手持两把锟斤拷 口中疾呼烫烫烫 脚踏千朵屯屯屯 笑看万物锘锘锘
我们非常熟悉的“烫烫烫”只有在Microsodt VC 在的debug 模式下才会出现。 VC会把未使用的内存空间全部填入 0xCC ,比如在声明变量却没有赋值而且还调用的情况下。在中文的环境下,与askll码对于一个字节不同,中文字符对于两个字节。 而在GBK内码下(类似askll码 , 将二进制数 转化为中文字符 ), 0xCCCC 对应的中文字符就是 烫
空の上の森の中の
所以编译器到底在干什么?
很多人都听说了C是一种高级语言,编译器把高级语言翻译成低级语言,操作系统把低级语言翻译成机器码。
那么我们可以看一看编译器翻译后的代码,来关注一下程序到底是什么运作的。
一般情况下,我们可以直接调用编译器来输出汇编代码,以helloworld.c为例。
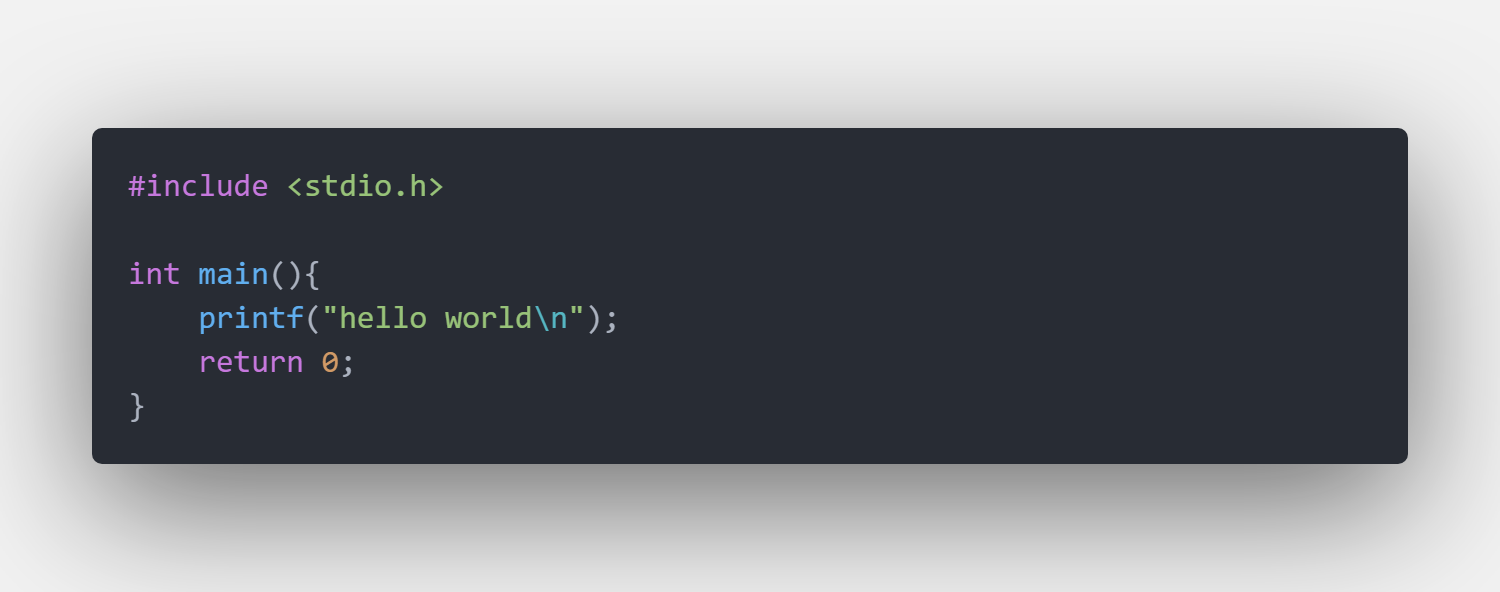
打开终端,输入命令
$ gcc -S helloworld.c -Og -masm=intel
gcc 代表使用的编译器, gcc编译C files, g++编译 Cpp files, 类似的还有clang 和 clang++)
-S 表示输出汇编程序 (-o表示生成可执行文件)
-Og是编译器的优化等级,让编译器不要做过多的优化,随着编译技术的提升,现在编译器几乎等于已经把你的程序重新写一遍了 (类似的还有 -O2 -O1)
-masm=intel 表示使用intel的语法,便于理解
当然可以用文末的在线工具(推荐)
然后就可以得到汇编代码
简单的说,
| sub | 在内存中开辟了一段空间【栈】 (注:这里的栈和数据解构的栈是不一样的) |
|---|---|
| lea | load effective address |
| call | 调用 puts ( printf ) 输出了这段内存上所存的数据 ( 即helloworld ),,把.LC0地址放入rdi ,也就是printf的第一个参数。 |
| mov | 将eax寄存器移到栈顶(0位) |
| add | 将add的第二个参数加到第一个参数上,在这里是rsp += 8 |
| ret | 返回 |
帰らぬ者と、待ち続けた者たち

不知道各位在编程中有没有出现过这种事情(笑
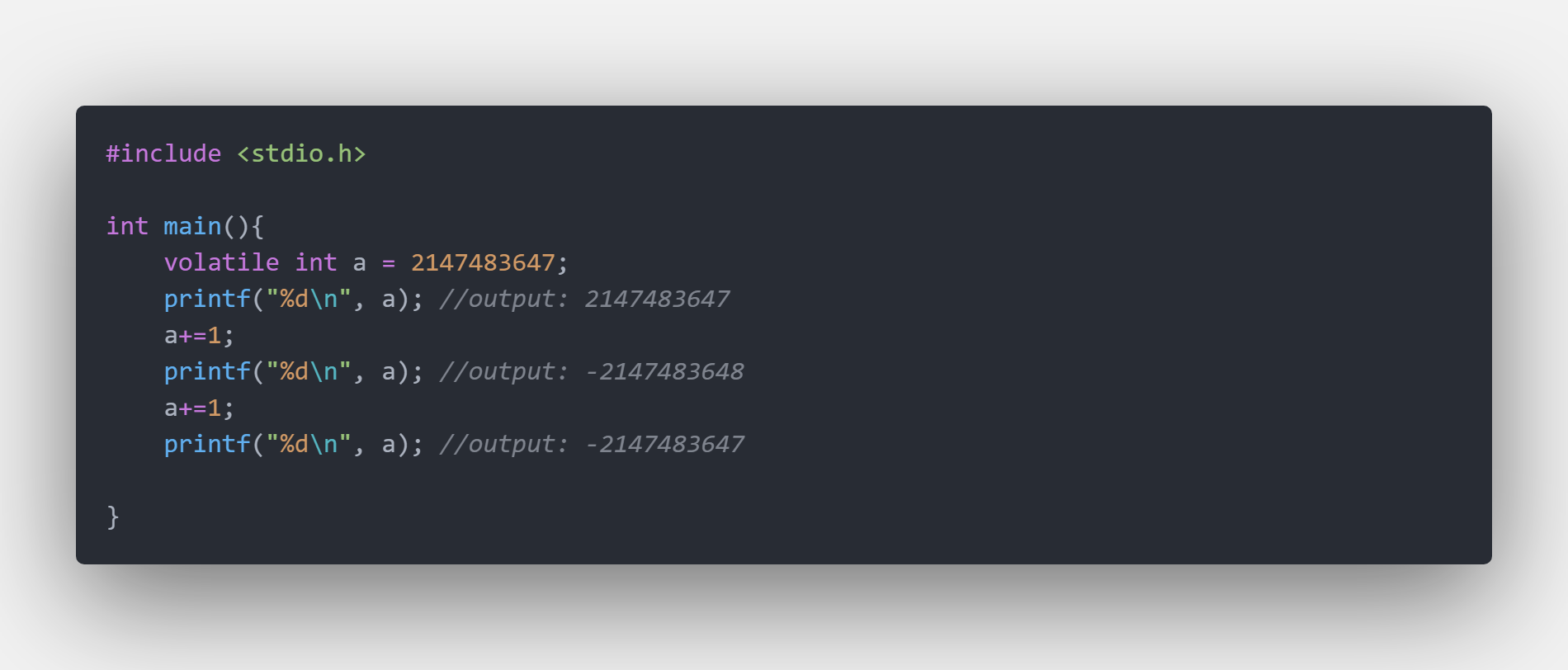
正如前文所指出的,C并没有边界检查,C不是一门高精度语言,所以在做大数运算的时候会导致精度丢失,数据溢出等问题。比如上图所展示的那样。这是很奇特的性质,具体解释会在资料中给出。
int型最高位是符号位,所以当达到int的最大值的时候符号位由表示正数的0变为表示复数的1,并且由于用补码储存的缘故,得到了如图所示的输出。
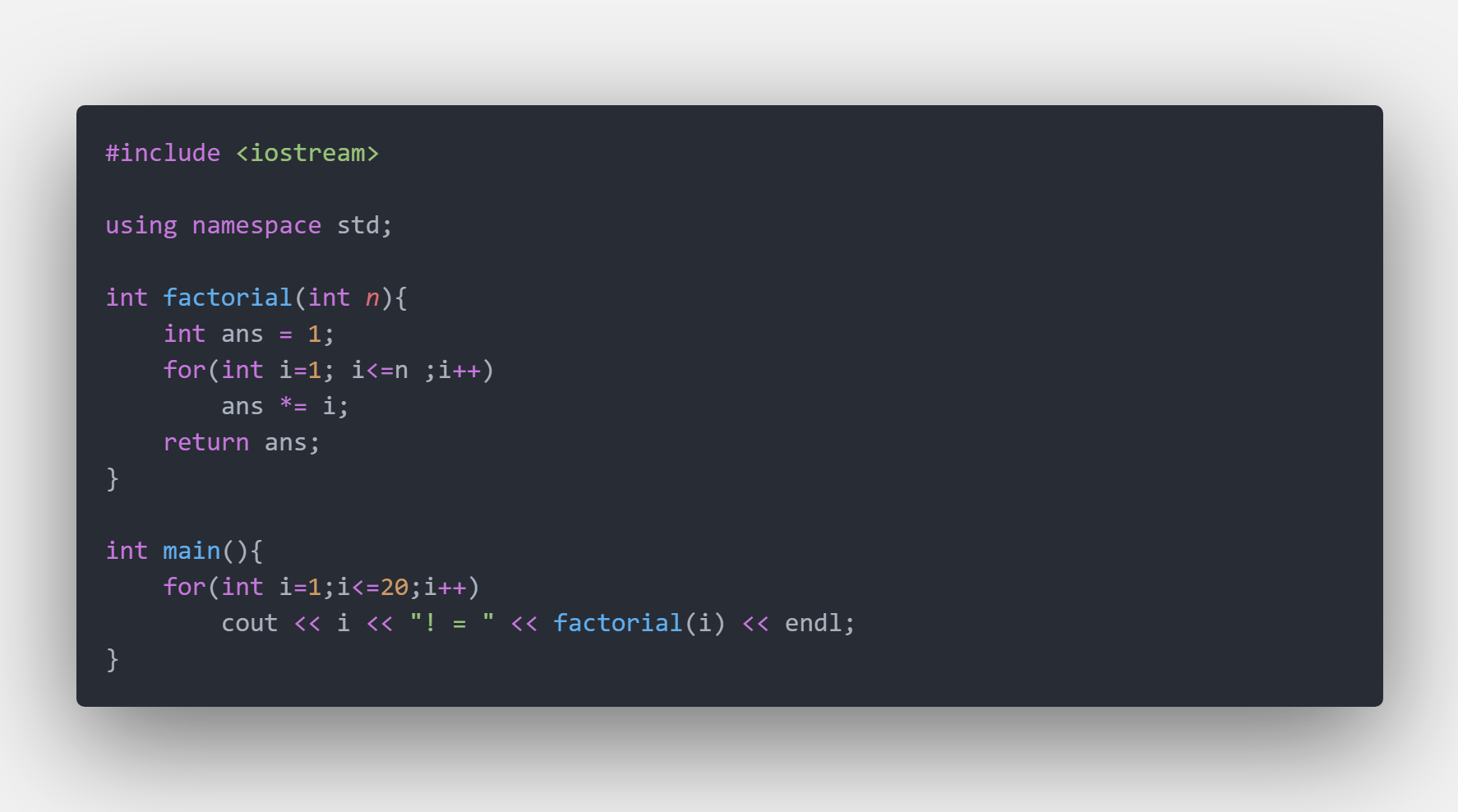
有时候我们会在程序中用到很大的数字,比如算组合数的时候有些程序会使用阶乘来计算。当n过大的时候,有时候阶乘算出来就不怎么准确了。
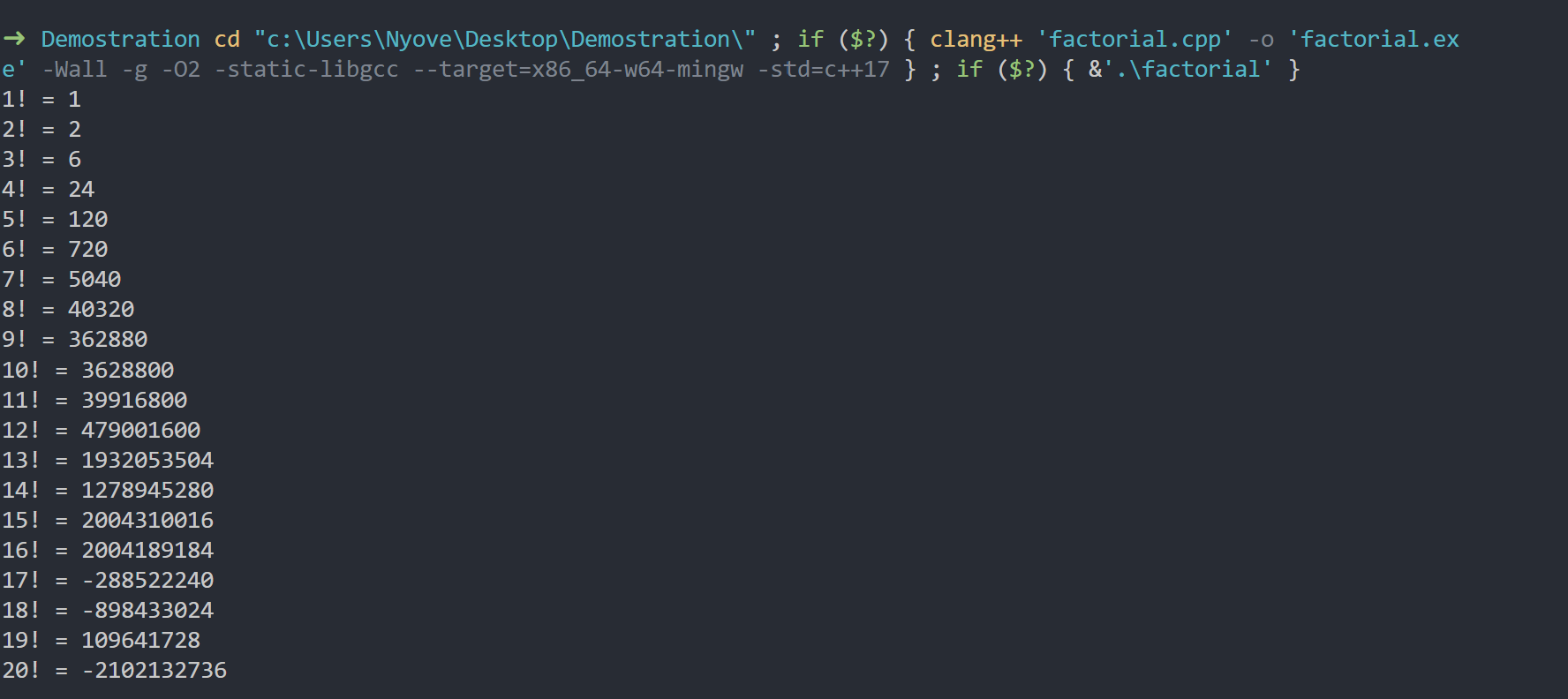
当然,你可以用尽最大的数据类型,甚至舍弃符号位,用unsigned long long 的数据类型(也就是夸张的0 ~ 2^64 ,八字节),但是问题实际上并没有解决。
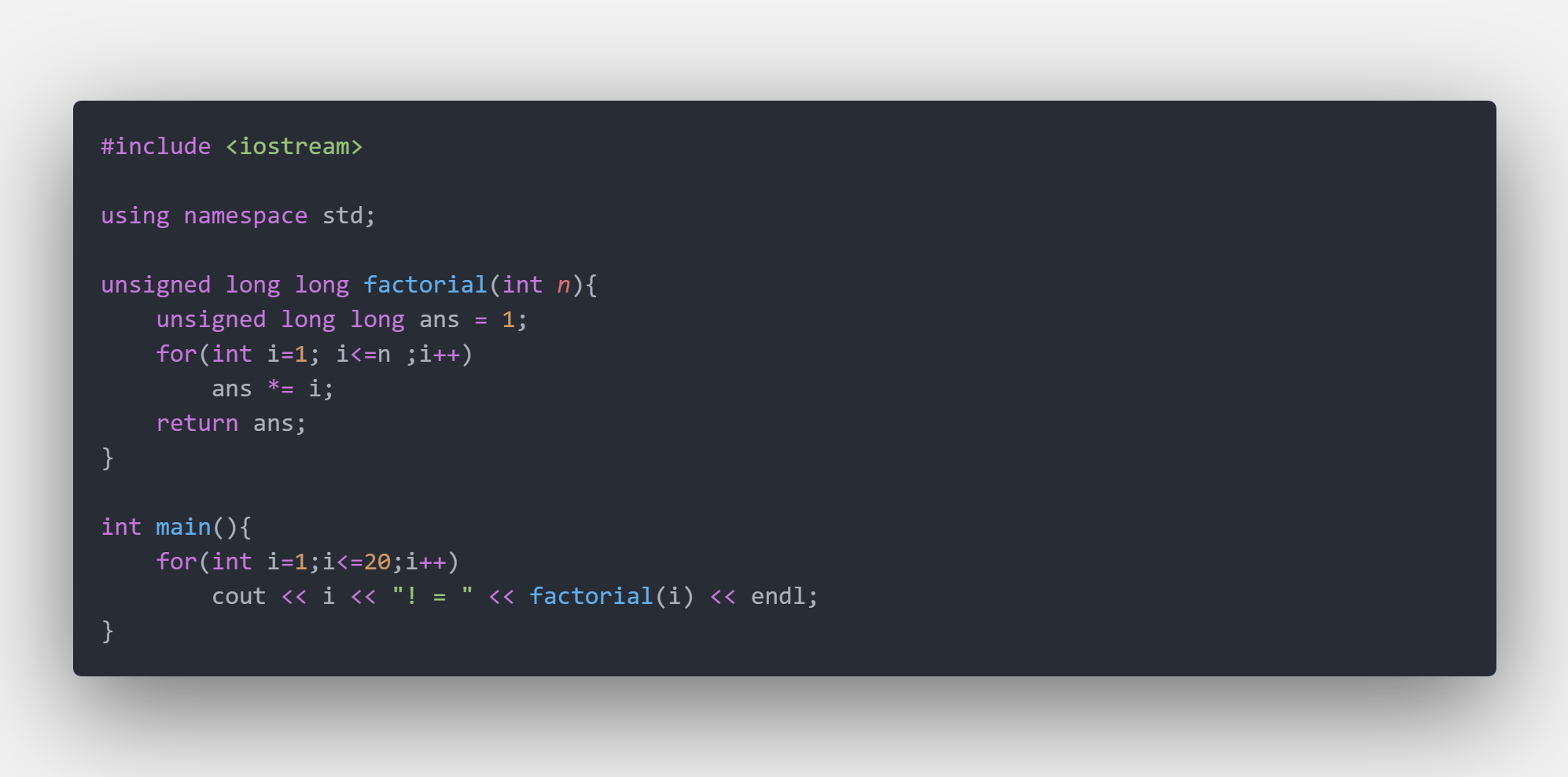
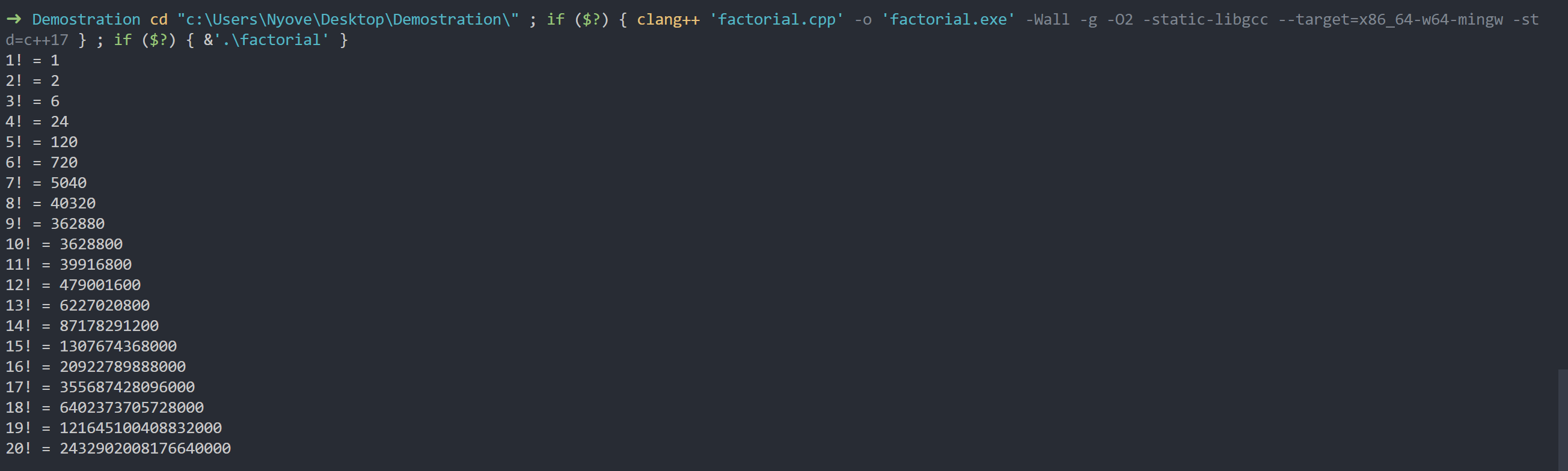
虽然我们可以确保20以内的阶乘的值是精确的(事实上21!就出现问题了,而且因为 unsigned long long 没有符号位的特性,和int不一样,它不是负数,而是看似正确的一个极大的正数)。但是在算组合数的依旧值得注意“算术溢出”的问题。
$$ C_{40}^{20} = \frac{40!}{20!20!} $$ 在运算过程中,编译器会自动进行数据类型转换,尽可能的存下这些数据,但是如果数据过大,仍然会产生溢出。
所以在写程序的时候应该适当的考虑一下内存和时间的边界问题。因为本质上计算机是在拿有限的空间去表示无限的数字。对于过大的数据,可以选择更加高明的算法来解决。组合数的算法有四种写法,你知道吗?
ただいま帰りました
在Mid-Term中有这么一道题:
汇编结果是:
可以用动图解释:
どうか、忘れないで
基于本文,可以给出一下优化程序的建议:
关注数据类型和内存边界问题
由上文带来的算法优化问题,能否用算法来解决数据类型和内存大小的限制
其它内存相关的优化(比如考虑内存的连续性,考虑减少不必要的调用和引用)
etc
设计模式
工厂模式
C++ 是 一门 OOP 语言, C++ 有多态,存在着继承关系的类。与现实类似,C++模式中的工厂通过一个工厂类,产生对应的子类。对于复杂的代码,比如之前的几次作业,可以方便我们理解。
原则
1 DONT REPEAT YOURSELF 2 MAKE THINGS AS LOCAL AS POSSIBLE